RustFS для современных озер данных
Современные озера данных и архитектуры озер домов строятся на современном объектном хранилище. Это означает, что они строятся на RustFS.
RustFS предоставляет унифицированное решение для хранения современных озер данных/озер домов, которое может работать где угодно: частное облако, публичное облако, колокационные центры, голое железо - даже на краю. Да, быстро, масштабируемо, облачно и готово к работе - батареи включены.
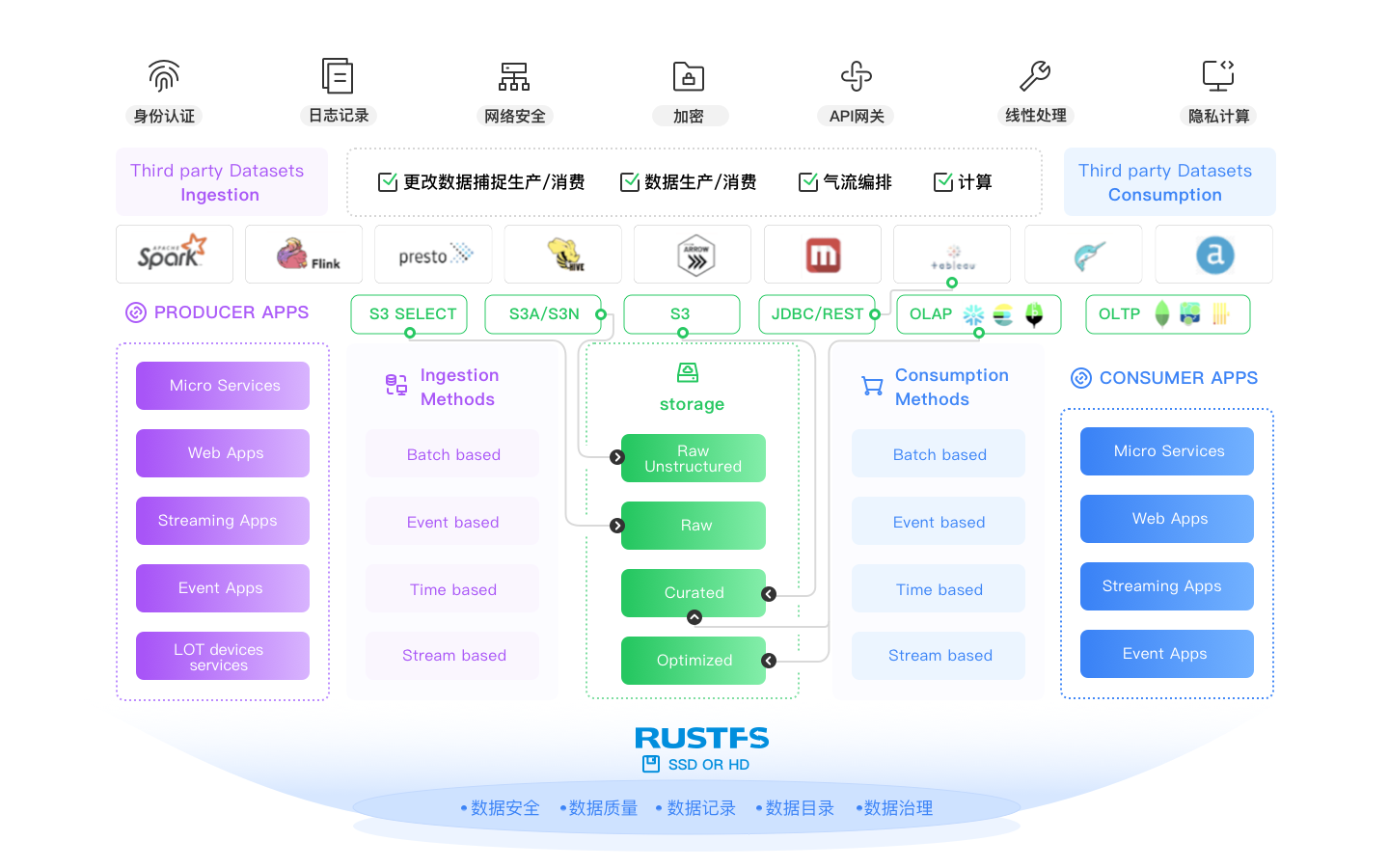
Готовность к открытым табличным форматам
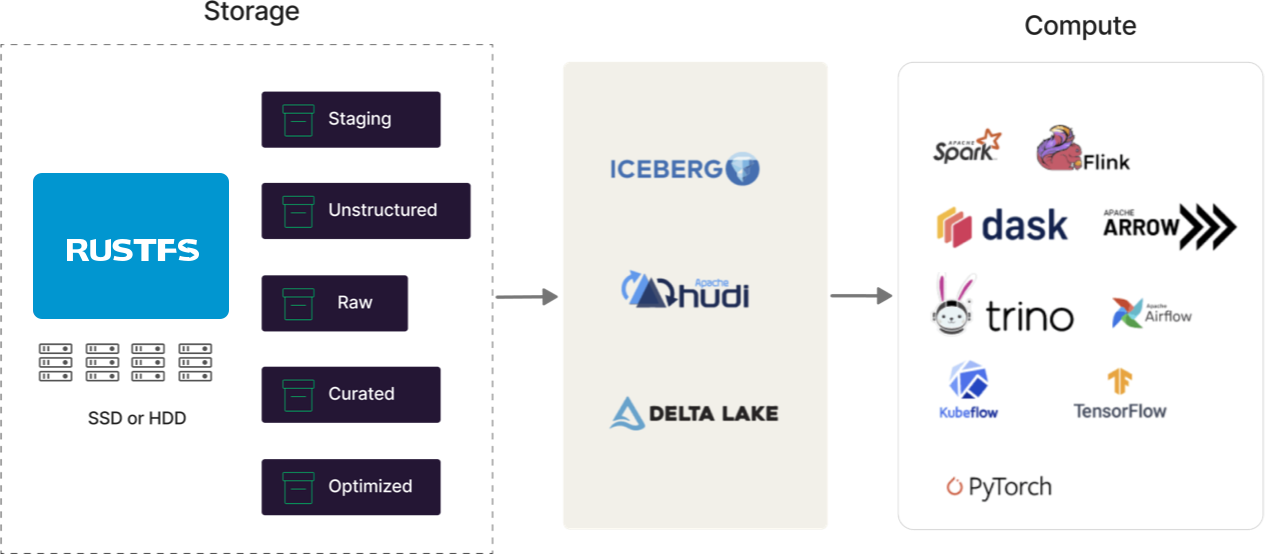
Современные озера данных являются многодвижковыми, и эти движки (Spark, Flink, Trino, Arrow, Dask и т.д.) должны быть связаны в некоторой связной архитектуре. Современные озера данных должны обеспечивать центральное хранение таблиц, переносимые метаданные, контроль доступа и постоянную структуру. Именно здесь в игру вступают такие форматы, как Iceberg, Hudi и Delta Lake. Они разработаны для современных озер данных, и RustFS поддерживает каждый из них. У нас могут быть мнения о том, какой из них победит (вы всегда можете спросить нас...), но мы привержены их поддержке до тех пор, пока это не потеряет смысл (см. Docker Swarm и Mesosphere).
Облачная нативность
RustFS родился в облаке и работает на облачных принципах - контейнеризация, оркестрация, микросервисы, API, инфраструктура как код и автоматизация. Благодаря этому экосистема облачной нативности "просто работает" с RustFS - от Spark до Presto/Trino, от Snowflake до Dremio, от NiFi до Kafka, от Prometheus до OpenObserve, от Istio до Linkerd, от Hashicorp Vault до Keycloak.
Не верьте нам на слово - введите вашу любимую облачно-нативную технологию и позвольте Google предоставить доказательства.
Многодвижковость
RustFS поддерживает все S3-совместимые движки запросов, то есть все из них. Не видите тот, который используете - напишите нам, и мы изучим вопрос.


Производительность
Современные озера данных требуют уровня производительности, и что еще более важно, производительности в масштабе, о которой старые хранилища товарного класса эпохи Hadoop могли только мечтать. RustFS доказал в множественных бенчмарках, что он превосходит Hadoop, и пути миграции хорошо документированы. Это означает, что движки запросов (Spark, Presto, Trino, Snowflake, Microsoft SQL Server, Teradata и т.д.) работают лучше. Это также включает ваши платформы AI/ML - от MLflow до Kubeflow.
Мы публикуем наши бенчмарки для всего мира и делаем их воспроизводимыми. Узнайте, как мы достигли 325 ГиБ/с (349 ГБ/с) на GET и 165 ГиБ/с (177 ГБ/с) на PUT с всего лишь 32 готовыми NVMe SSD узлами в этой статье.
Легковесность
Серверный бинарный файл RustFS составляет < 100 МБ в своей полноте. Несмотря на свою мощь, он достаточно надежен для работы в центрах обработки данных, но все еще достаточно мал, чтобы комфортно жить на краю. Нет такой альтернативы в мире Hadoop. Для предприятий это означает, что ваши S3-приложения могут получать доступ к данным где угодно с тем же API. Реализуя граничные местоположения RustFS и возможности репликации, мы можем захватывать и фильтровать данные на краю и доставлять их в родительский кластер для агрегации и дальнейшей аналитической реализации.
Декомпозиция
Современные озера данных расширяют возможности декомпозиции, которые разбили Hadoop. Современные озера данных имеют высокоскоростные движки обработки запросов и высокопропускное хранилище. Современные озера данных слишком большие, чтобы поместиться в базах данных, поэтому данные размещаются в объектном хранилище. Таким образом, базы данных могут сосредоточиться на функциональности оптимизации запросов и передать функциональность хранения высокоскоростному объектному хранилищу. Храня подмножества данных в памяти и используя такие функции, как pushdown предикатов (S3 Select) и внешние таблицы - движки запросов имеют большую гибкость.
Открытый исходный код
Предприятия, которые приняли Hadoop, делали это из предпочтения технологий с открытым исходным кодом. Как логический преемник - предприятия также хотят, чтобы их озера данных имели открытый исходный код. Именно поэтому процветает Iceberg и почему Databricks открыл исходный код Delta Lake.
Возможности, свобода от привязки и комфорт, которые приходят от десятков тысяч пользователей, имеют реальную ценность. RustFS также является 100% открытым исходным кодом, обеспечивая организациям возможность остаться верными своим целям при инвестировании в современные озера данных.
Быстрый рост
Данные постоянно генерируются, что означает, что они должны постоянно поступать - не вызывая несварения. RustFS создан для этого мира и работает из коробки с Kafka, Flink, RabbitMQ и множеством других решений. Результатом является то, что озеро данных/озеро дом становится единым источником истины, который может бесшовно масштабироваться до эксабайтов и далее.
RustFS имеет множественных клиентов с ежедневным поступлением данных, превышающим 250ПБ.
Простота
Простота сложна. Она требует работы, дисциплины и, самое главное, приверженности. Простота RustFS легендарна и является философской приверженностью, которая делает наше программное обеспечение легким для развертывания, использования, обновления и масштабирования. Современные озера данных не должны быть сложными. Есть несколько частей, и мы привержены обеспечению того, чтобы RustFS был самым легким для принятия и развертывания.
ELT или ETL - просто работает
RustFS не только работает с каждым протоколом потоковой передачи данных, но и с каждым конвейером данных - каждый протокол потоковой передачи данных и конвейер данных работают с RustFS. Каждый поставщик был обширно протестирован, и обычно конвейеры данных имеют устойчивость и производительность.
Устойчивость
RustFS защищает данные, используя встроенное кодирование стирания для каждого объекта, что намного более эффективно, чем альтернативы репликации HDFS, которые никогда не принимались. Дополнительно, обнаружение битового гниения RustFS гарантирует, что он никогда не читает поврежденные данные - динамически захватывая и восстанавливая поврежденные данные для объектов. RustFS также поддерживает межрегиональную активную-активную репликацию. Наконец, RustFS поддерживает полную платформу блокировки объектов, предоставляющую юридическое удержание и сохранение (с режимами управления и соответствия).
Программно определяемый
Преемник Hadoop HDFS - это не аппаратное устройство, а программное обеспечение, работающее на товарном оборудовании. Это суть RustFS - программное обеспечение. Как и Hadoop HDFS, RustFS разработан для полного использования преимуществ товарных серверов. Способный использовать диски NVMe и сети 100 GbE, RustFS может сжимать центры обработки данных, тем самым улучшая операционную эффективность и управляемость. Фактически, компании, строящие альтернативные озера данных, сокращают свой аппаратный отпечаток на 60% или более, улучшая производительность и сокращая количество FTE, необходимых для управления им.
Безопасность
RustFS поддерживает множественные сложные схемы серверного шифрования для защиты данных, где бы они ни находились, в полете или в покое. Подход RustFS обеспечивает конфиденциальность, целостность и подлинность с незначительными накладными расходами производительности. Поддержка серверного и клиентского шифрования с использованием AES-256-GCM, ChaCha20-Poly1305 и AES-CBC обеспечивает совместимость приложений. Дополнительно, RustFS поддерживает ведущие в отрасли системы управления ключами (KMS).