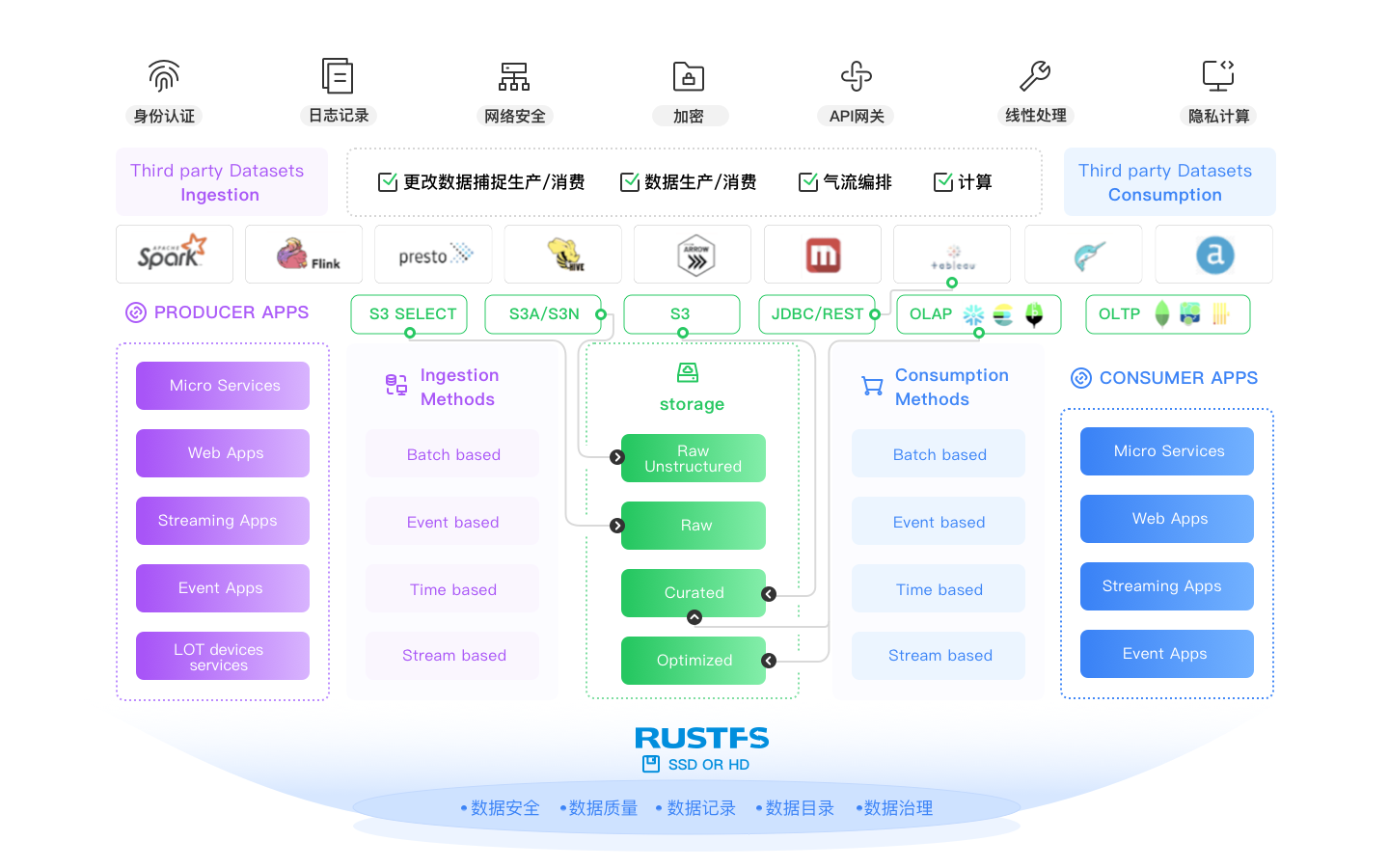
RustFS for Modern Data Lakes
Modern data lakes and lakehouse architectures are built on modern object storage. This means they are built on RustFS.
RustFS provides a unified storage solution for modern data lakes/lakehouses that can run anywhere: private cloud, public cloud, colos, bare metal - even at the edge. Yes, fast, scalable, cloud-native and ready to go - batteries included.
Open Table Format Ready
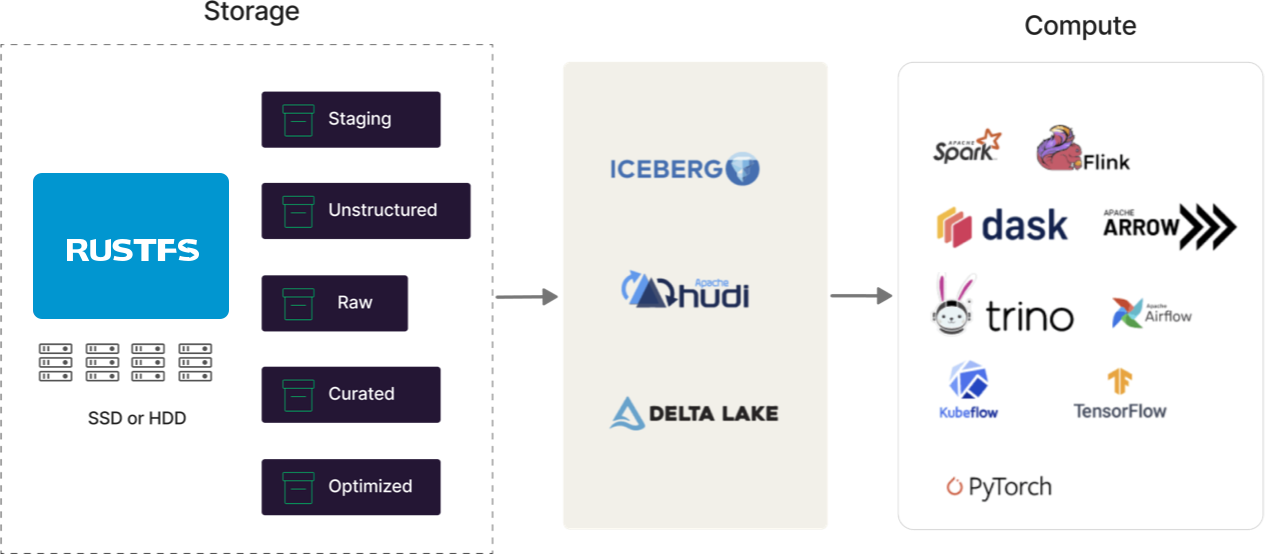
Modern data lakes are multi-engine, and these engines (Spark, Flink, Trino, Arrow, Dask, etc.) all need to be bound together in some cohesive architecture. Modern data lakes must provide central table storage, portable metadata, access control, and persistent structure. This is where formats like Iceberg, Hudi, and Delta Lake come into play. They are designed for modern data lakes, and RustFS supports each of them. We may have opinions on which one will win (you can always ask us...), but we are committed to supporting them until it doesn't make sense (see Docker Swarm and Mesosphere).
Cloud Native
RustFS was born in the cloud and operates on cloud principles - containerization, orchestration, microservices, APIs, infrastructure as code, and automation. Because of this, the cloud-native ecosystem "just works" with RustFS - from Spark to Presto/Trino, from Snowflake to Dremio, from NiFi to Kafka, from Prometheus to OpenObserve, from Istio to Linkerd, from Hashicorp Vault to Keycloak.
Don't take our word for it - enter your favorite cloud-native technology and let Google provide the evidence.
Multi-Engine
RustFS supports all S3-compatible query engines, which is to say all of them. Don't see the one you use - drop us a line and we'll investigate.


Performance
Modern data lakes require a level of performance, and even more importantly, performance at scale that the old Hadoop-era commodity stores could only dream of. RustFS has proven in multiple benchmarks that it outperforms Hadoop, and migration paths are well documented. This means query engines (Spark, Presto, Trino, Snowflake, Microsoft SQL Server, Teradata, etc.) perform better. This also includes your AI/ML platforms - from MLflow to Kubeflow.
We publish our benchmarks for the world to see and make them reproducible. Learn how we achieved 325 GiB/s (349 GB/s) on GET and 165 GiB/s (177 GB/s) on PUT with just 32 off-the-shelf NVMe SSD nodes in this article.
Lightweight
RustFS's server binary is < 100 MB in its entirety. Despite its power, it's robust enough to run in data centers but still small enough to live comfortably at the edge. There's no such alternative in the Hadoop world. For enterprises, this means your S3 applications can access data anywhere with the same API. By implementing RustFS edge locations and replication capabilities, we can capture and filter data at the edge and deliver it to the parent cluster for aggregation and further analytical implementation.
Decomposition
Modern data lakes extend the decomposition capabilities that broke up Hadoop. Modern data lakes have high-speed query processing engines and high-throughput storage. Modern data lakes are too large to fit in databases, so data resides in object storage. This way, databases can focus on query optimization functionality and outsource storage functionality to high-speed object storage. By keeping subsets of data in memory and leveraging features like predicate pushdown (S3 Select) and external tables - query engines have greater flexibility.
Open Source
Enterprises that adopted Hadoop did so out of preference for open source technology. As the logical successor - enterprises want their data lakes to be open source as well. This is why Iceberg is thriving and why Databricks open-sourced Delta Lake.
The capabilities, freedom from lock-in, and comfort that come from tens of thousands of users have real value. RustFS is also 100% open source, ensuring organizations can stay true to their goals when investing in modern data lakes.
Rapid Growth
Data is constantly being generated, which means it must be constantly ingested - without causing indigestion. RustFS is built for this world and works out of the box with Kafka, Flink, RabbitMQ, and numerous other solutions. The result is that the data lake/lakehouse becomes a single source of truth that can seamlessly scale to exabytes and beyond.
RustFS has multiple customers with daily data ingestion exceeding 250PB.
Simplicity
Simplicity is hard. It requires work, discipline, and most importantly, commitment. RustFS's simplicity is legendary and is a philosophical commitment that makes our software easy to deploy, use, upgrade, and scale. Modern data lakes don't have to be complex. There are a few parts, and we're committed to ensuring RustFS is the easiest to adopt and deploy.
ELT or ETL - It Just Works
RustFS doesn't just work with every data streaming protocol, but every data pipeline - every data streaming protocol and data pipeline works with RustFS. Every vendor has been extensively tested, and typically, data pipelines have resilience and performance.
Resilience
RustFS protects data using inline erasure coding for each object, which is far more efficient than the HDFS replication alternatives that were never adopted. Additionally, RustFS's bitrot detection ensures it never reads corrupted data - capturing and repairing corrupted data dynamically for objects. RustFS also supports cross-region, active-active replication. Finally, RustFS supports a complete object locking framework providing legal hold and retention (with governance and compliance modes).
Software Defined
The successor to Hadoop HDFS is not a hardware appliance but software running on commodity hardware. This is the essence of RustFS - software. Like Hadoop HDFS, RustFS is designed to take full advantage of commodity servers. Able to leverage NVMe drives and 100 GbE networks, RustFS can shrink data centers, thereby improving operational efficiency and manageability. In fact, companies building alternative data lakes reduce their hardware footprint by 60% or more while improving performance and reducing the FTEs required to manage it.
Security
RustFS supports multiple sophisticated server-side encryption schemes to protect data wherever it resides, whether in flight or at rest. RustFS's approach ensures confidentiality, integrity, and authenticity with negligible performance overhead. Server-side and client-side encryption support using AES-256-GCM, ChaCha20-Poly1305, and AES-CBC ensures application compatibility. Additionally, RustFS supports industry-leading key management systems (KMS).