RustFS para Lagos de Datos Modernos
Los lagos de datos modernos y las arquitecturas lakehouse se construyen sobre almacenamiento de objetos moderno. Esto significa que se construyen sobre RustFS.
RustFS proporciona una solución de almacenamiento unificada para lagos de datos/lakehouses modernos que puede ejecutarse en cualquier lugar: nube privada, nube pública, colocaciones, bare metal - incluso en el edge. Sí, rápido, escalable, cloud-native y listo para usar - baterías incluidas.
Listo para Formatos de Tabla Abiertos
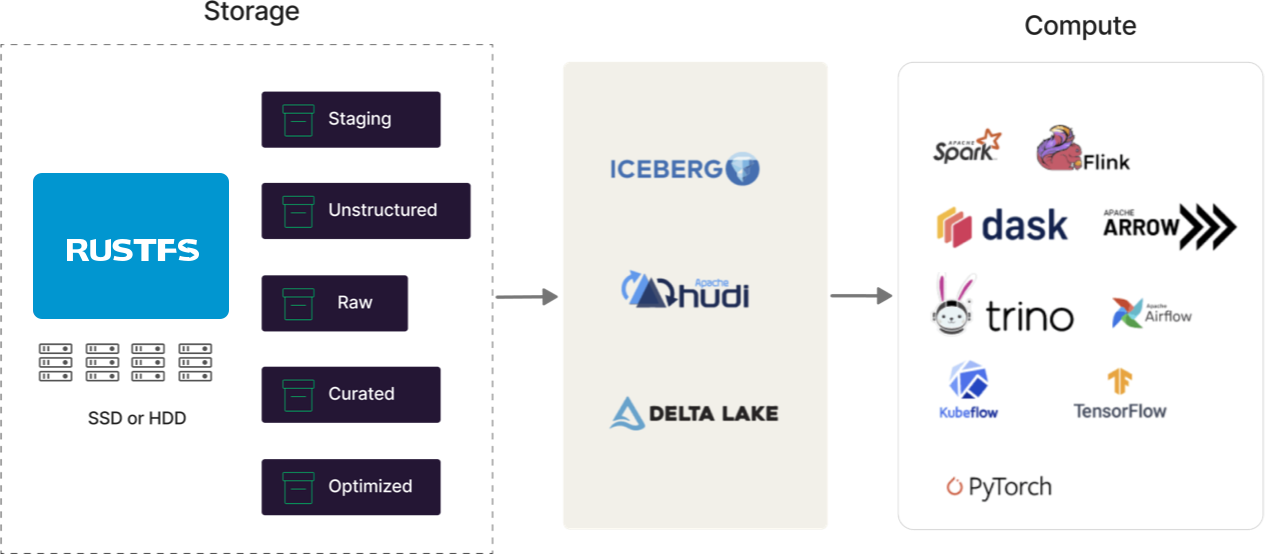
Los lagos de datos modernos son multi-motor, y estos motores (Spark, Flink, Trino, Arrow, Dask, etc.) todos necesitan estar unidos en alguna arquitectura cohesiva. Los lagos de datos modernos deben proporcionar almacenamiento central de tablas, metadatos portables, control de acceso y estructura persistente. Aquí es donde entran en juego formatos como Iceberg, Hudi y Delta Lake. Están diseñados para lagos de datos modernos, y RustFS los admite a todos. Podemos tener opiniones sobre cuál ganará (siempre puedes preguntarnos...), pero estamos comprometidos a admitirlos hasta que no tenga sentido (ver Docker Swarm y Mesosphere).
Cloud Native
RustFS nació en la nube y opera bajo principios de nube - contenerización, orquestación, microservicios, APIs, infraestructura como código, y automatización. Debido a esto, el ecosistema cloud-native "simplemente funciona" con RustFS - desde Spark hasta Presto/Trino, desde Snowflake hasta Dremio, desde NiFi hasta Kafka, desde Prometheus hasta OpenObserve, desde Istio hasta Linkerd, desde Hashicorp Vault hasta Keycloak.
No nos creas bajo palabra - ingresa tu tecnología cloud-native favorita y deja que Google proporcione la evidencia.
Multi-Motor
RustFS admite todos los motores de consulta compatibles con S3, que es decir todos ellos. ¿No ves el que usas? Escríbenos y lo investigaremos.


Rendimiento
Los lagos de datos modernos requieren un nivel de rendimiento, y aún más importante, rendimiento a escala que las tiendas de productos básicos de la era Hadoop solo podían soñar. RustFS ha demostrado en múltiples benchmarks que supera a Hadoop, y las rutas de migración están bien documentadas. Esto significa que los motores de consulta (Spark, Presto, Trino, Snowflake, Microsoft SQL Server, Teradata, etc.) funcionan mejor. Esto también incluye tus plataformas de AI/ML - desde MLflow hasta Kubeflow.
Publicamos nuestros benchmarks para que el mundo los vea y los hagamos reproducibles. Aprende cómo logramos 325 GiB/s (349 GB/s) en GET y 165 GiB/s (177 GB/s) en PUT con solo 32 nodos NVMe SSD estándar en este artículo.
Liviano
El binario del servidor de RustFS es < 100 MB en su totalidad. A pesar de su poder, es lo suficientemente robusto para ejecutarse en centros de datos pero aún lo suficientemente pequeño para vivir cómodamente en el edge. No hay tal alternativa en el mundo Hadoop. Para las empresas, esto significa que tus aplicaciones S3 pueden acceder a datos en cualquier lugar con la misma API. Al implementar ubicaciones edge de RustFS y capacidades de replicación, podemos capturar y filtrar datos en el edge y entregarlos al cluster padre para agregación e implementación analítica adicional.
Descomposición
Los lagos de datos modernos extienden las capacidades de descomposición que rompieron Hadoop. Los lagos de datos modernos tienen motores de procesamiento de consultas de alta velocidad y almacenamiento de alto rendimiento. Los lagos de datos modernos son demasiado grandes para caber en bases de datos, por lo que los datos residen en almacenamiento de objetos. De esta manera, las bases de datos pueden enfocarse en la funcionalidad de optimización de consultas y externalizar la funcionalidad de almacenamiento al almacenamiento de objetos de alta velocidad. Al mantener subconjuntos de datos en memoria y aprovechar características como predicate pushdown (S3 Select) y tablas externas - los motores de consulta tienen mayor flexibilidad.
Código Abierto
Las empresas que adoptaron Hadoop lo hicieron por preferencia por la tecnología de código abierto. Como el sucesor lógico - las empresas quieren que sus lagos de datos también sean de código abierto. Por esto es que Iceberg está prosperando y por qué Databricks hizo open source de Delta Lake.
Las capacidades, libertad del vendor lock-in, y comodidad que vienen de decenas de miles de usuarios tienen valor real. RustFS también es 100% código abierto, asegurando que las organizaciones puedan mantenerse fieles a sus objetivos al invertir en lagos de datos modernos.
Crecimiento Rápido
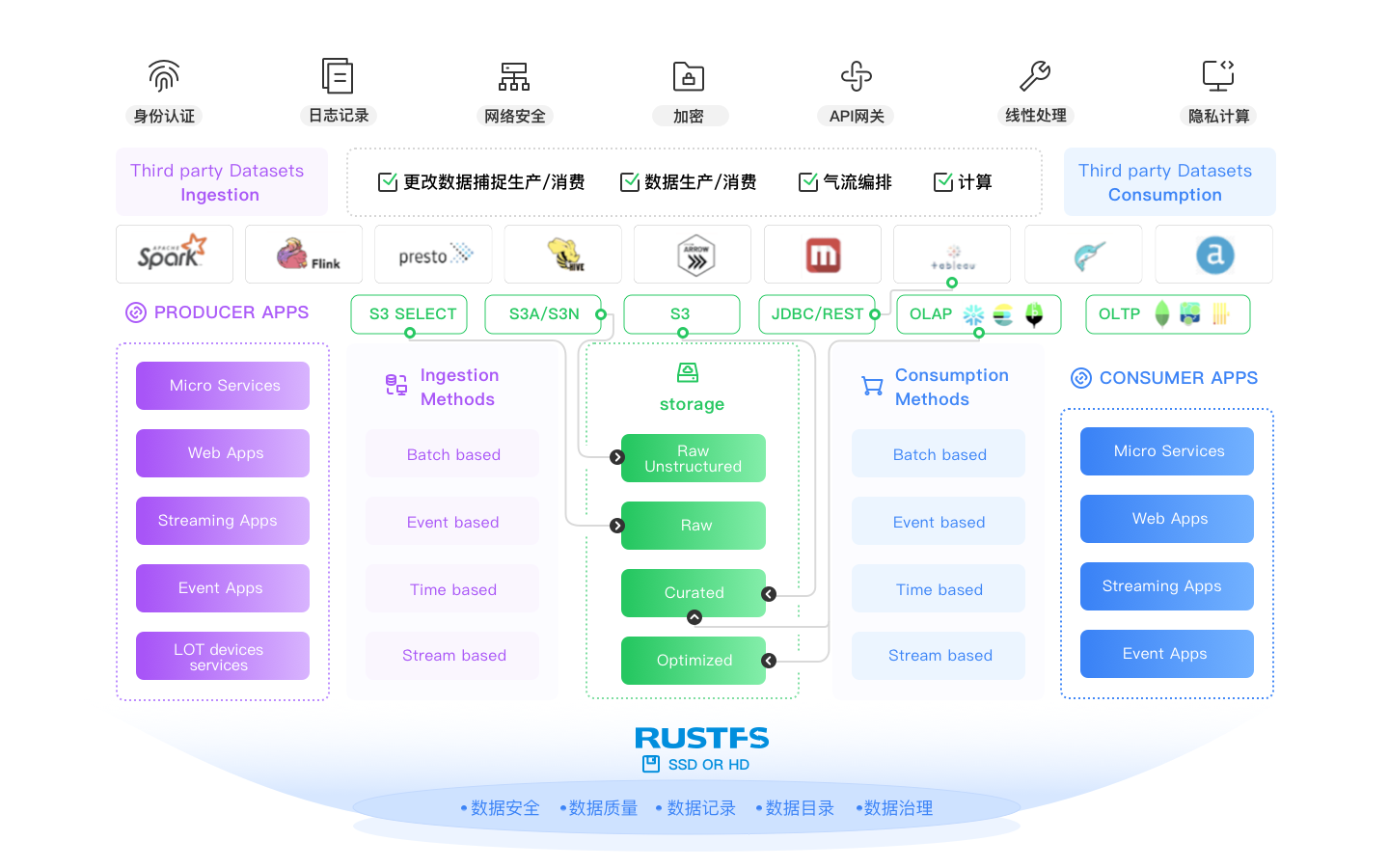
Los datos se están generando constantemente, lo que significa que deben ser ingeridos constantemente - sin causar indigestión. RustFS está construido para este mundo y funciona out of the box con Kafka, Flink, RabbitMQ, y numerosas otras soluciones. El resultado es que el lago de datos/lakehouse se convierte en una sola fuente de verdad que puede escalar sin problemas a exabytes y más allá.
RustFS tiene múltiples clientes con ingesta diaria de datos que excede los 250PB.
Simplicidad
La simplicidad es difícil. Requiere trabajo, disciplina, y más importante, compromiso. La simplicidad de RustFS es legendaria y es un compromiso filosófico que hace que nuestro software sea fácil de desplegar, usar, actualizar y escalar. Los lagos de datos modernos no tienen que ser complejos. Hay pocas partes, y estamos comprometidos a asegurar que RustFS sea el más fácil de adoptar y desplegar.
ELT o ETL - Simplemente Funciona
RustFS no solo funciona con cada protocolo de streaming de datos, sino con cada pipeline de datos - cada protocolo de streaming de datos y pipeline de datos funciona con RustFS. Cada proveedor ha sido extensivamente probado, y típicamente, los pipelines de datos tienen resistencia y rendimiento.
Resistencia
RustFS protege datos usando codificación de borrado en línea para cada objeto, que es mucho más eficiente que las alternativas de replicación HDFS que nunca fueron adoptadas. Adicionalmente, la detección de bitrot de RustFS asegura que nunca lee datos corruptos - capturando y reparando datos corruptos dinámicamente para objetos. RustFS también admite replicación cross-region, active-active. Finalmente, RustFS admite un marco completo de bloqueo de objetos proporcionando retención legal y retención (con modos de governance y compliance).
Definido por Software
El sucesor a Hadoop HDFS no es un appliance de hardware sino software ejecutándose en hardware commodity. Esta es la esencia de RustFS - software. Como Hadoop HDFS, RustFS está diseñado para aprovechar completamente los servidores commodity. Capaz de aprovechar unidades NVMe y redes 100 GbE, RustFS puede encoger centros de datos, mejorando así la eficiencia operacional y manejabilidad. De hecho, las empresas que construyen lagos de datos alternativos reducen su huella de hardware en 60% o más mientras mejoran el rendimiento y reducen los FTEs requeridos para gestionarlo.
Seguridad
RustFS admite múltiples esquemas sofisticados de cifrado del lado del servidor para proteger datos donde sea que residan, ya sea en tránsito o en reposo. El enfoque de RustFS asegura confidencialidad, integridad y autenticidad con sobrecarga de rendimiento negligible. El soporte de cifrado del lado del servidor y del lado del cliente usando AES-256-GCM, ChaCha20-Poly1305, y AES-CBC asegura compatibilidad de aplicaciones. Adicionalmente, RustFS admite sistemas líderes en la industria de gestión de claves (KMS).