RustFS pour les Lacs de Données Modernes
Les lacs de données modernes et les lakehouses sont construits sur un stockage d'objets moderne. Cela signifie qu'ils sont construits sur RustFS.
RustFS fournit une solution de stockage unifiée pour les lacs de données/lakehouses modernes qui peuvent s'exécuter partout : cloud privé, cloud public, colocations, bare metal - même à la périphérie. Oui, rapide, évolutif, cloud-natif et prêt à l'emploi - batteries incluses.
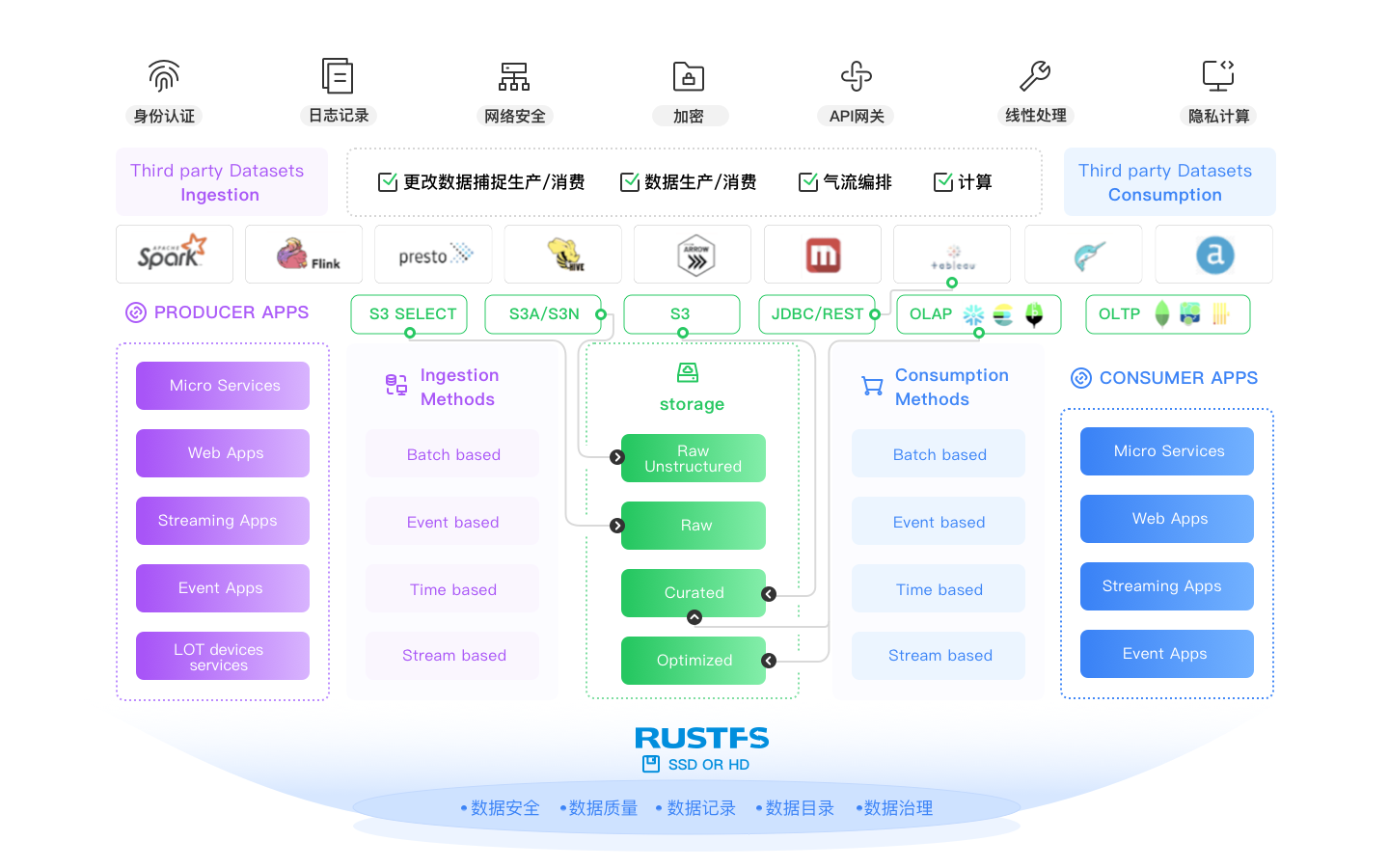
Prêt pour les Formats de Tables Ouverts
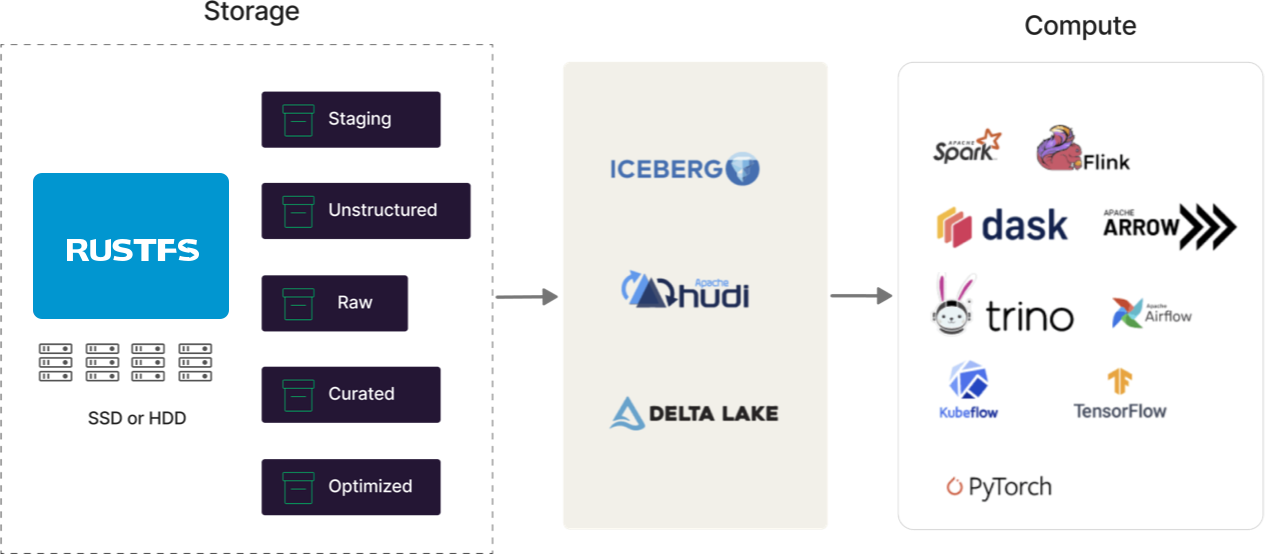
Les lacs de données modernes sont multi-moteurs, ces moteurs (Spark, Flink, Trino, Arrow, Dask, etc.) ont tous besoin d'être liés d'une manière ou d'une autre en une architecture cohérente. Les lacs de données modernes doivent fournir un stockage de tables central, un déploiement portable, un contrôle d'accès et une structure durable. C'est là que des formats comme Iceberg, Hudi et Delta Lake entrent en jeu. Ils sont conçus pour les lacs de données modernes, et RustFS les prend tous en charge. Nous pourrions avoir une opinion sur qui gagne (vous pouvez toujours nous demander...) mais nous nous engageons à les soutenir jusqu'à ce que cela n'ait plus de sens (voir Docker Swarm et Mesosphere).
Cloud-Natif
RustFS est né dans le cloud et adhère aux principes cloud du modèle opérationnel - conteneurisation, orchestration, microservices, API, infrastructure en tant que code et automatisation. Pour cette raison, l'écosystème cloud-natif "fonctionne simplement" avec RustFS - de Spark à Presto/Trino, de Snowflake à Dremio, de Nifi à Kafka, de Prometheus à OpenObserve, d'Istio à Linkerd, de Hashicorp Vault à Keycloak.
Ne nous croyez pas sur parole - tapez votre technologie cloud-native préférée et laissez Google vous fournir la preuve.
Multi-Moteurs
RustFS prend en charge tous les moteurs de requête compatibles S3, c'est-à-dire tous. Vous n'en voyez pas un que vous utilisez - laissez-nous un message, nous enquêterons.


Performance
Les lacs de données modernes nécessitent un certain niveau de performance, et plus important encore, de performance à l'échelle, que les anciens magasins d'objets de type Hadoop ne pouvaient que rêver d'atteindre. RustFS a prouvé dans plusieurs benchmarks qu'il surpasse Hadoop et les chemins de migration ont été clairement documentés. Cela signifie que les moteurs de requête (Spark, Presto, Trino, Snowflake, Microsoft SQL Server, Teradata, etc.) fonctionnent mieux. Cela inclut également vos plateformes AI/ML - de MLflow à Kubeflow.
Nous publions nos benchmarks pour que le monde entier les voit et les rendons reproductibles. Apprenez comment nous atteignons 325 GiB/s (349 GB/s) en GET et 165 GiB/s (177 GB/s) en PUT dans cet article avec seulement 32 nœuds NVMe SSD prêts à l'emploi.
Léger
Les binaires serveur de RustFS font tous < 100 MB. Malgré sa petite taille, il est suffisamment puissant pour fonctionner dans le centre de données, mais encore assez petit pour vivre confortablement à la périphérie. Il n'y a pas d'alternative similaire dans le monde Hadoop. Cela signifie pour l'entreprise que vos applications S3 peuvent accéder aux données avec la même API n'importe où, à tout moment. En implémentant des emplacements périphériques RustFS et des fonctionnalités de réplication, nous pouvons capturer et filtrer les données à la périphérie et les transmettre au cluster mère pour l'agrégation et une analyse plus poussée.
Découplé
Les lacs de données modernes étendent les capacités de découplage qui ont été utilisées pour briser Hadoop. Les lacs de données modernes ont des moteurs de traitement de requêtes haute vitesse et ils ont un stockage haute performance. Les lacs de données modernes sont trop volumineux pour tenir dans une base de données, donc les données résident dans le stockage d'objets. De cette façon, la base de données peut se concentrer sur les capacités d'optimisation des requêtes et externaliser les capacités de stockage vers un stockage d'objets haute vitesse. En gardant des sous-ensembles de données en mémoire et en exploitant des techniques comme le pushdown de prédicats (S3 Select) et les tables externes - les moteurs de requête ont plus de flexibilité.
Open Source
Les entreprises qui ont adopté Hadoop l'ont fait par préférence pour la technologie open source. En tant que successeur logique - les entreprises veulent que leur DataLake soit également open source. C'est pourquoi Iceberg prospère et pourquoi Databricks a rendu Delta Lake open source.
Il y a une valeur réelle dans la vérifiabilité, l'absence de verrouillage et le confort qui vient des dizaines de milliers d'utilisateurs. RustFS est également 100% open source, garantissant que les organisations peuvent rester fidèles à leurs objectifs lors de l'investissement dans les lacs de données modernes.
Ingestion Rapide
Les données sont générées en permanence, ce qui signifie qu'elles doivent être ingérées en permanence - sans causer d'indigestion. RustFS est conçu pour ce monde, prêt à l'emploi, avec Kafka, Flink, RabbitMQ et une foule d'autres solutions. Le résultat est que le datalake/datalakehouse devient la source unique de vérité qui peut évoluer de manière transparente vers l'exabyte et au-delà.
RustFS a plusieurs clients avec une ingestion de données quotidienne dépassant 250 PB.
Simplicité
La simplicité est difficile. Cela demande du travail, de la discipline et surtout, de l'engagement. La simplicité de RustFS est légendaire et est un engagement philosophique pour rendre notre logiciel facile à déployer, utiliser, mettre à niveau et étendre. Les lacs de données modernes ne doivent pas être compliqués. Il y a quelques pièces et nous nous engageons à nous assurer que RustFS soit le plus facile à adopter et à déployer.
ELT ou ETL - Ça Marche Simplement
Non seulement RustFS fonctionne avec chaque protocole de streaming de données et chaque pipeline de données, mais chaque protocole de streaming de données et pipeline de données fonctionne avec RustFS. Chaque fournisseur a été largement testé et en général, les pipelines de données sont résilients et performants.
Résilience
RustFS protège les données en utilisant l'effacement en ligne par objet, qui est bien plus efficace que l'alternative de réplication HDFS de l'époque et qui n'a jamais été adoptée. De plus, la détection de corruption binaire de RustFS garantit qu'il ne lit jamais de données corrompues - capturant et réparant la corruption de manière dynamique par objet. RustFS prend également en charge la réplication inter-région, active-active. Enfin, RustFS prend en charge un cadre complet de verrouillage d'objets fournissant la conservation légale et la rétention (avec gouvernance et conformité).
Défini par Logiciel
Le successeur de Hadoop HDFS n'est pas un appareil matériel, mais un logiciel fonctionnant sur du matériel standard. C'est l'essence de RustFS - logiciel. Comme Hadoop HDFS, RustFS est conçu pour tirer parti des serveurs standard. Capable d'exploiter les lecteurs NVMe et les réseaux 100 GbE, RustFS peut réduire l'empreinte du centre de données, améliorant ainsi l'efficacité opérationnelle et la gérabilité. En fait, les entreprises construisant des lacs de données de remplacement réduisent leur empreinte matérielle de 60% ou plus tout en améliorant les performances et en réduisant les ETP nécessaires pour les gérer.
Sécurité
RustFS prend en charge plusieurs schémas de chiffrement côté serveur sophistiqués pour protéger les données, peu importe où elles se trouvent, qu'elles soient en transit ou au repos. L'approche de RustFS garantit la confidentialité, l'intégrité et l'authenticité avec un surcoût de performance négligeable. Le support de chiffrement côté serveur et côté client utilise AES-256-GCM, ChaCha20-Poly1305 et AES-CBC, garantissant la compatibilité des applications. De plus, RustFS prend en charge les systèmes de gestion de clés (KMS) leaders de l'industrie.