Réplication multi-sites active-active pour stockage d'objets
Réplication active pour stockage d'objets
La réplication active pour le stockage d'objets est une exigence critique pour les environnements de production critiques. RustFS est actuellement le seul fournisseur à offrir ce service. Exécutée au niveau de granularité du bucket, elle est utilisée dans les situations suivantes :
RustFS prend en charge la réplication synchrone et quasi-synchrone, selon les choix d'architecture et le taux de changement des données. Dans chacun des cas ci-dessus, la réplication doit être aussi proche que possible de la cohérence stricte (compte tenu des considérations de bande passante et du taux de changement).
La réplication de données RustFS est conçue pour la résilience à grande échelle
Les fonctionnalités principales incluent :
- ✅ Objets chiffrés ou non chiffrés et leurs métadonnées associées (écrites atomiquement avec l'objet)
- ✅ Versions d'objets
- ✅ Étiquettes d'objets (si présentes)
- ✅ Informations de rétention de verrouillage d'objets S3 (si présentes)
Caractéristiques principales
Capacité pour les buckets source et destination d'avoir le même nom
Ceci est requis pour les applications qui doivent basculer de manière transparente vers un site distant sans aucune interruption.
Support natif de la réplication automatique de verrouillage/rétention d'objets entre source et destination
Assure que les exigences d'intégrité des données et de conformité sont maintenues pendant le processus de réplication.
Réplication quasi-synchrone
Peut mettre à jour les objets immédiatement après toute mutation se produisant dans le bucket. RustFS suit une cohérence stricte au sein des centres de données et une cohérence éventuelle entre les centres de données pour protéger les données.
Fonctionnalités de notification
Fonctionnalités de notification pour pousser les événements d'échec de réplication. Les applications peuvent s'abonner à ces événements et alerter les équipes opérationnelles.
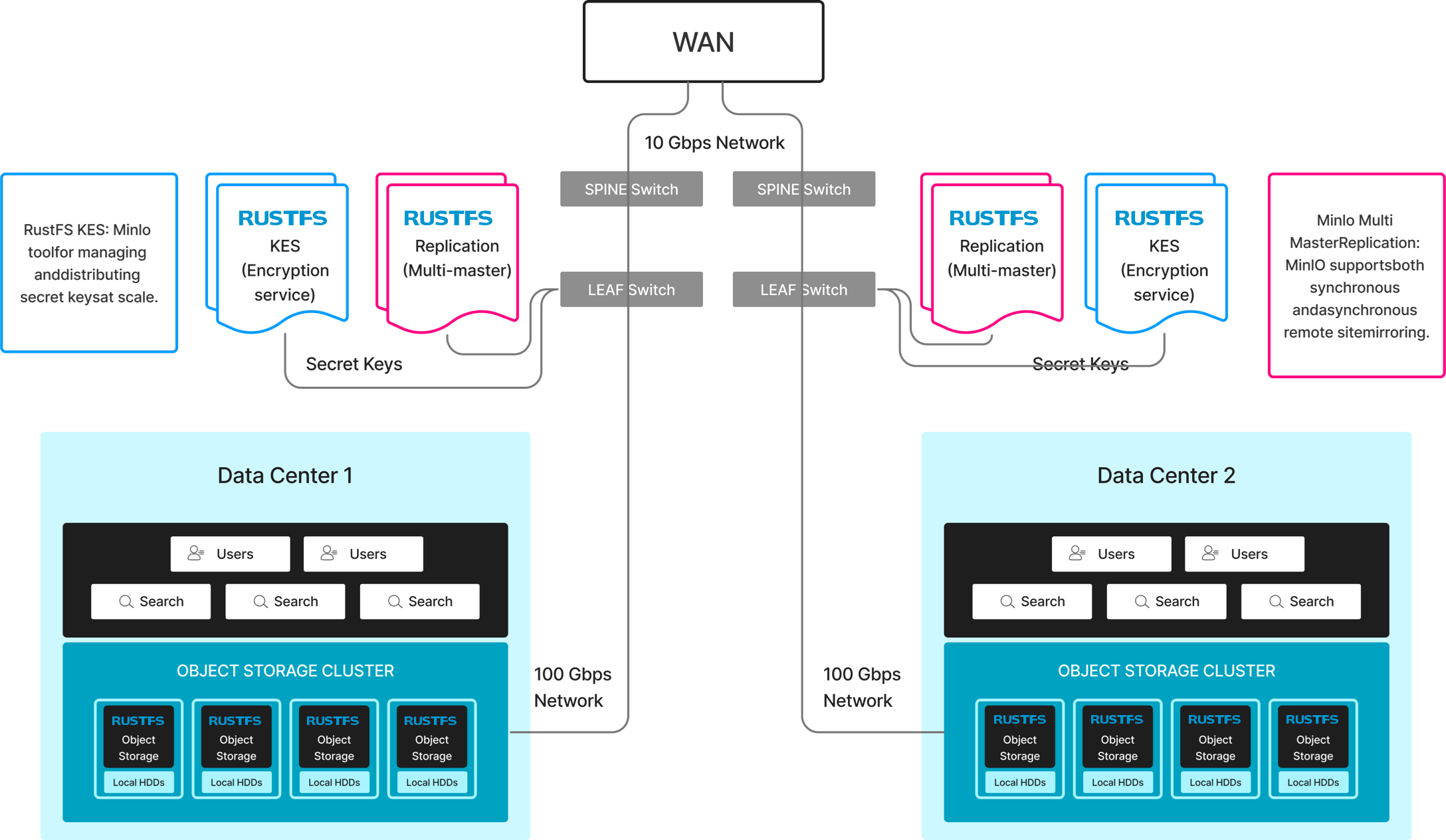
Considérations lors de l'implémentation de la réplication active-active de RustFS
Au niveau le plus fondamental, toute conception doit prendre en compte l'infrastructure, la bande passante, la latence, la résilience et l'échelle. Examinons-les dans l'ordre :
Infrastructure
RustFS recommande d'utiliser le même matériel aux deux extrémités des points de terminaison de réplication. Bien que du matériel similaire puisse fonctionner, l'introduction de profils matériels hétérogènes introduit de la complexité et ralentit l'identification des problèmes.
Bande passante
La bande passante est un facteur important pour maintenir les deux sites toujours synchronisés. L'exigence optimale de bande passante entre les sites est déterminée par le taux de données entrantes. Spécifiquement, si la bande passante est insuffisante pour gérer les pics, les changements seront mis en file d'attente vers le site distant et finiront par se synchroniser.
Latence
Après la bande passante, la latence est la considération la plus importante lors de la conception d'un modèle actif-actif. La latence représente le temps d'aller-retour (RTT) entre deux clusters RustFS. L'objectif est de réduire la latence au plus petit nombre possible dans les contraintes budgétaires imposées par la bande passante. RustFS recommande un seuil RTT ne dépassant pas 20 millisecondes pour les liaisons Ethernet et les réseaux, avec un taux de perte de paquets ne dépassant pas 0,01%.
Architecture
Actuellement, RustFS recommande uniquement la réplication entre deux centres de données. La réplication peut être effectuée entre plusieurs centres de données, cependant, la complexité impliquée et les compromis nécessaires rendent cela assez difficile.
Architecture de déploiement à grande échelle
RustFS prend en charge de très grands déploiements dans chaque centre de données, incluant source et destination, les considérations ci-dessus détermineront l'échelle.
Questions fréquemment posées
Que se passe-t-il lorsque la destination de réplication tombe en panne ?
Si la destination tombe, la source mettra en cache les changements et commencera la synchronisation une fois que la destination de réplication sera restaurée. Il peut y avoir un certain délai pour atteindre la synchronisation complète, selon la durée, le nombre de changements, la bande passante et la latence.
Quels sont les arguments pour l'immutabilité ?
L'immutabilité est prise en charge. Les concepts clés peuvent être trouvés dans cet article. En mode de réplication active-active, l'immutabilité ne peut être garantie que lorsque les objets sont versionnés. Le versioning ne peut pas être désactivé sur la source. Si le versioning est suspendu sur la destination, RustFS commencera à échouer la réplication.
Quels sont les autres impacts si le versioning est suspendu ou s'il y a une discordance ?
Dans ces cas, la réplication peut échouer. Par exemple, si vous essayez de désactiver le versioning sur le bucket source, une erreur sera retournée. Vous devez d'abord supprimer la configuration de réplication avant de pouvoir désactiver le versioning sur le bucket source. De plus, si le versioning est désactivé sur le bucket de destination, la réplication échouera.
Comment est-ce géré si le verrouillage d'objets n'est pas activé aux deux extrémités ?
Le verrouillage d'objets doit être activé sur la source et la destination. Il y a un cas extrême où après avoir configuré la réplication de bucket, le bucket de destination peut être supprimé et recréé mais sans le verrouillage d'objets activé, la réplication peut échouer. S'il y a des paramètres de verrouillage d'objets mal configurés aux deux extrémités, des situations incohérentes peuvent survenir. Dans ce cas, RustFS échouera silencieusement.