현대적인 데이터 레이크를 위한 RustFS
현대적인 데이터 레이크와 레이크하우스 아키텍처는 현대적인 객체 스토리지 위에 구축됩니다. 이는 RustFS 위에 구축됨을 의미합니다.
RustFS는 어디서나 실행할 수 있는 현대적인 데이터 레이크/레이크하우스를 위한 통합 스토리지 솔루션을 제공합니다: 프라이빗 클라우드, 퍼블릭 클라우드, 코로케이션, 베어메탈 - 심지어 엣지에서도. 네, 빠르고, 확장 가능하며, 클라우드 네이티브이고 즉시 사용 가능합니다 - 배터리 포함.
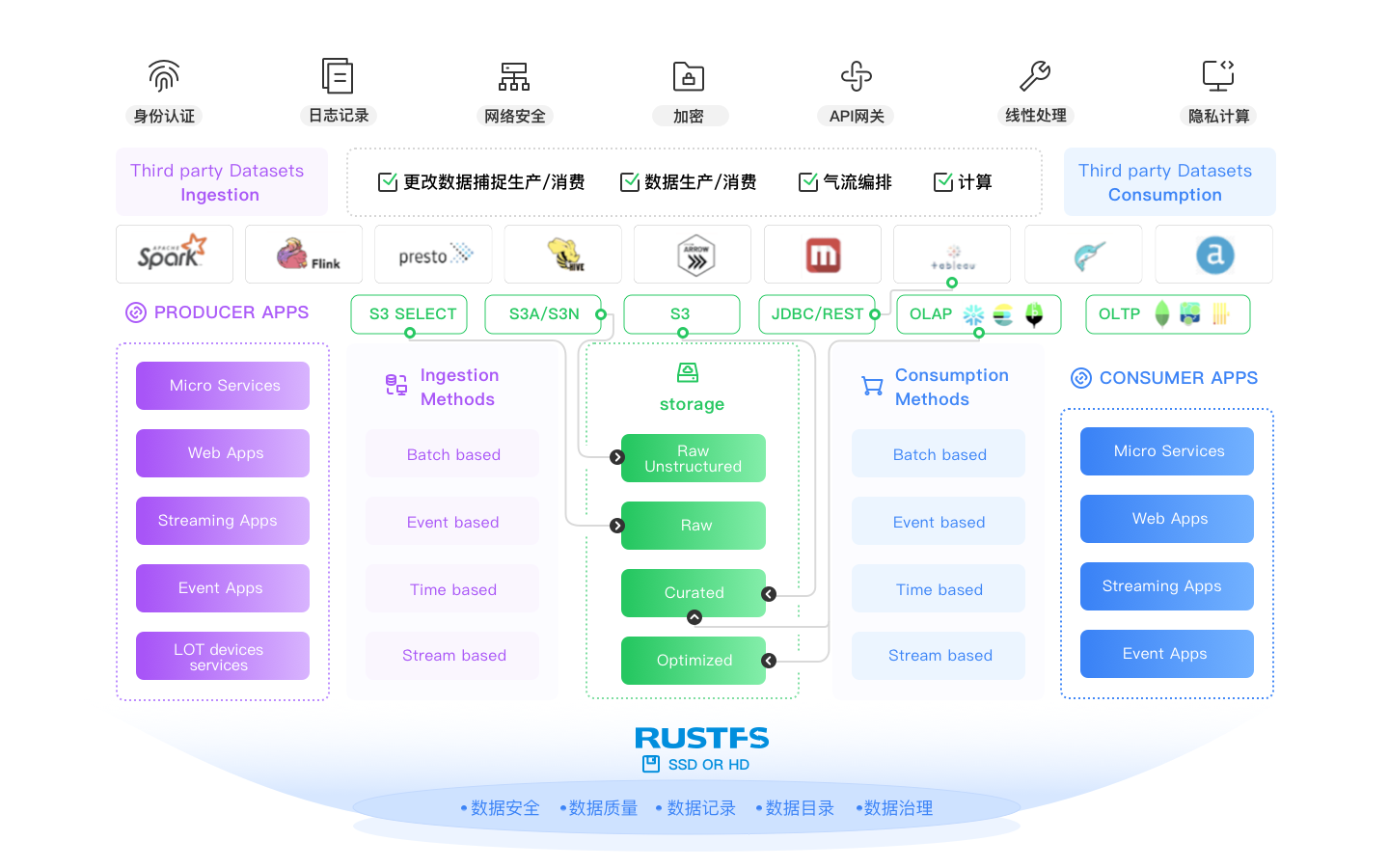
오픈 테이블 형식 준비
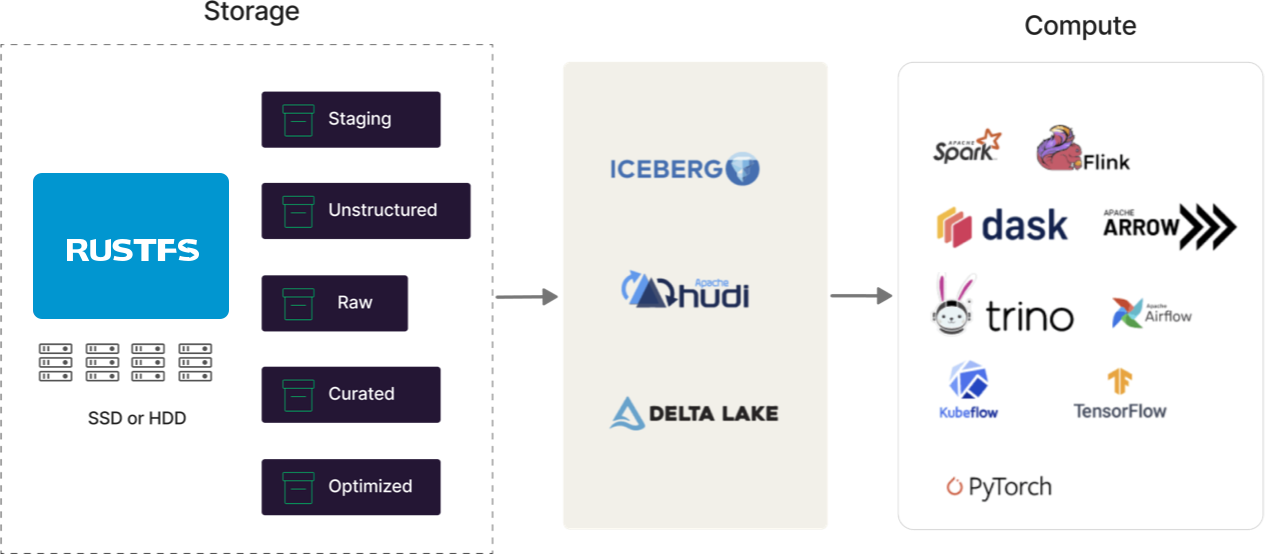
현대적인 데이터 레이크는 다중 엔진이며, 이러한 엔진들(Spark, Flink, Trino, Arrow, Dask 등)은 모두 어떤 응집력 있는 아키텍처에서 함께 바인딩되어야 합니다. 현대적인 데이터 레이크는 중앙 테이블 스토리지, 이식 가능한 메타데이터, 액세스 제어 및 지속적인 구조를 제공해야 합니다. 바로 여기서 Iceberg, Hudi, Delta Lake와 같은 형식이 등장합니다. 이들은 현대적인 데이터 레이크를 위해 설계되었으며 RustFS는 각각을 지원합니다. 어떤 것이 승리할지에 대한 의견이 있을 수도 있지만(언제든지 문의하세요...), 의미가 없을 때까지 지원하기로 약속했습니다(Docker Swarm과 Mesosphere 참조).
클라우드 네이티브
RustFS는 클라우드에서 태어났으며 클라우드 원칙에 따라 작동합니다 - 컨테이너화, 오케스트레이션, 마이크로서비스, API, 코드형 인프라 및 자동화. 이 때문에 클라우드 네이티브 생태계가 RustFS와 "그냥 작동"합니다 - Spark부터 Presto/Trino까지, Snowflake부터 Dremio까지, NiFi부터 Kafka까지, Prometheus부터 OpenObserve까지, Istio부터 Linkerd까지, Hashicorp Vault부터 Keycloak까지.
우리 말을 믿지 마시고, 즐겨 사용하는 클라우드 네이티브 기술을 입력하고 Google이 증거를 제공하도록 하세요.
다중 엔진
RustFS는 모든 S3 호환 쿼리 엔진을 지원합니다. 즉, 모든 것을 지원합니다. 사용하는 것이 보이지 않으면 연락 주시면 조사하겠습니다.


성능
현대적인 데이터 레이크는 어느 정도의 성능을 필요로 하고, 더 중요하게는 오래된 Hadoop 시대의 범용 스토어가 꿈꿀 수 있었던 규모의 성능이 필요합니다. RustFS는 여러 벤치마크에서 Hadoop을 능가한다는 것을 증명했으며, 마이그레이션 경로가 잘 문서화되어 있습니다. 이는 쿼리 엔진(Spark, Presto, Trino, Snowflake, Microsoft SQL Server, Teradata 등)이 더 나은 성능을 발휘함을 의미합니다. 이는 MLflow부터 Kubeflow까지 AI/ML 플랫폼도 포함합니다.
우리는 세계가 볼 수 있도록 벤치마크를 공개하고 재현 가능하게 만듭니다. 이 글에서 32개의 기성품 NVMe SSD 노드만으로 GET에서 325 GiB/s(349 GB/s), PUT에서 165 GiB/s(177 GB/s)를 달성한 방법을 배워보세요.
가벼움
RustFS의 서버 바이너리는 전체적으로 100MB 미만입니다. 강력함에도 불구하고 데이터 센터에서 실행하기에는 충분히 강력하지만 엣지에서도 편안하게 살기에는 충분히 작습니다. Hadoop 세계에는 그런 대안이 없습니다. 기업에게 이는 S3 애플리케이션이 동일한 API로 어디서나 데이터에 액세스할 수 있음을 의미합니다. RustFS 엣지 위치와 복제 기능을 구현함으로써 엣지에서 데이터를 캡처하고 필터링하고 집계 및 추가 분석 구현을 위해 부모 클러스터로 전달할 수 있습니다.
분해
현대적인 데이터 레이크는 Hadoop을 해체한 분해 기능을 확장합니다. 현대적인 데이터 레이크는 고속 쿼리 처리 엔진과 고처리량 스토리지를 갖습니다. 현대적인 데이터 레이크는 데이터베이스에 맞추기에는 너무 크므로 데이터는 객체 스토리지에 상주합니다. 이렇게 하면 데이터베이스는 쿼리 최적화 기능에 집중하고 스토리지 기능을 고속 객체 스토리지에 아웃소싱할 수 있습니다. 데이터 서브셋을 메모리에 유지하고 predicate pushdown(S3 Select) 및 외부 테이블과 같은 기능을 활용함으로써 쿼리 엔진이 더 큰 유연성을 갖습니다.
오픈 소스
Hadoop을 채택한 기업들은 오픈 소스 기술에 대한 선호도에서 그렇게 했습니다. 논리적 후계자로서 기업들은 데이터 레이크도 오픈 소스이기를 원합니다. 이것이 Iceberg가 번창하고 Databricks가 Delta Lake를 오픈 소스화한 이유입니다.
수만 명의 사용자로부터 오는 기능, 벤더 종속의 자유 및 편안함은 실제 가치가 있습니다. RustFS도 100% 오픈 소스이므로 현대적인 데이터 레이크에 투자할 때 조직이 목표에 충실할 수 있도록 보장합니다.
빠른 성장
데이터는 지속적으로 생성되고 있으며, 이는 소화 불량을 일으키지 않으면서 지속적으로 수집되어야 함을 의미합니다. RustFS는 이 세계를 위해 구축되었으며 Kafka, Flink, RabbitMQ 및 수많은 다른 솔루션과 즉시 작동합니다. 결과적으로 데이터 레이크/레이크하우스는 엑사바이트 이상으로 원활하게 확장할 수 있는 단일 진실 공급원이 됩니다.
RustFS는 일일 데이터 수집이 250PB를 초과하는 여러 고객을 보유하고 있습니다.
단순성
단순성은 어렵습니다. 작업, 규율, 그리고 가장 중요하게는 헌신이 필요합니다. RustFS의 단순성은 전설적이며 우리 소프트웨어를 배포, 사용, 업그레이드 및 확장하기 쉽게 만드는 철학적 약속입니다. 현대적인 데이터 레이크가 복잡할 필요는 없습니다. 몇 개의 부분이 있으며, RustFS가 채택하고 배포하기 가장 쉽도록 보장하기 위해 최선을 다하고 있습니다.
ELT 또는 ETL - 그냥 작동합니다
RustFS는 모든 데이터 스트리밍 프로토콜에서 작동할 뿐만 아니라 모든 데이터 파이프라인과도 작동합니다 - 모든 데이터 스트리밍 프로토콜과 데이터 파이프라인이 RustFS와 작동합니다. 모든 공급업체가 광범위하게 테스트되었으며, 일반적으로 데이터 파이프라인은 복원력과 성능을 갖습니다.
복원력
RustFS는 각 객체에 대해 인라인 소거 코딩을 사용하여 데이터를 보호하며, 이는 채택되지 않았던 HDFS 복제 대안보다 훨씬 효율적입니다. 또한 RustFS의 비트로트 감지는 손상된 데이터를 읽지 않도록 보장하며, 객체에 대해 손상된 데이터를 동적으로 캡처하고 복구합니다. RustFS는 또한 지역 간 액티브-액티브 복제를 지원합니다. 마지막으로 RustFS는 법적 보존과 retention(거버넌스 및 컴플라이언스 모드 포함)을 제공하는 완전한 객체 잠금 프레임워크를 지원합니다.
소프트웨어 정의
Hadoop HDFS의 후계자는 하드웨어 어플라이언스가 아니라 범용 하드웨어에서 실행되는 소프트웨어입니다. 이것이 RustFS의 본질입니다 - 소프트웨어. Hadoop HDFS와 마찬가지로 RustFS는 범용 서버를 최대한 활용하도록 설계되었습니다. NVMe 드라이브와 100 GbE 네트워크를 활용할 수 있어 RustFS는 데이터 센터를 축소하여 운영 효율성과 관리성을 향상시킬 수 있습니다. 실제로 대안 데이터 레이크를 구축하는 회사들은 성능을 향상시키고 관리에 필요한 FTE를 줄이면서 하드웨어 풋프린트를 60% 이상 줄입니다.
보안
RustFS는 데이터가 어디에 있든 - 전송 중이든 정적이든 - 데이터를 보호하는 여러 정교한 서버 측 암호화 방식을 지원합니다. RustFS의 접근 방식은 무시할 수 있는 성능 오버헤드로 기밀성, 무결성 및 진위성을 보장합니다. AES-256-GCM, ChaCha20-Poly1305, AES-CBC를 사용한 서버 측 및 클라이언트 측 암호화 지원은 애플리케이션 호환성을 보장합니다. 또한 RustFS는 업계 선도 키 관리 시스템(KMS)을 지원합니다.