RustFS für moderne Data Lakes
Moderne Data Lakes und Lakehouse-Architekturen basieren auf modernem Objektspeicher. Das bedeutet, sie basieren auf RustFS.
RustFS bietet eine einheitliche Speicherlösung für moderne Data Lakes/Lakehouses, die überall laufen kann: Private Cloud, Public Cloud, Colocation, Bare Metal - sogar am Edge. Ja, schnell, skalierbar, cloud-native und einsatzbereit - Batterien inbegriffen.
Open Table Format Ready
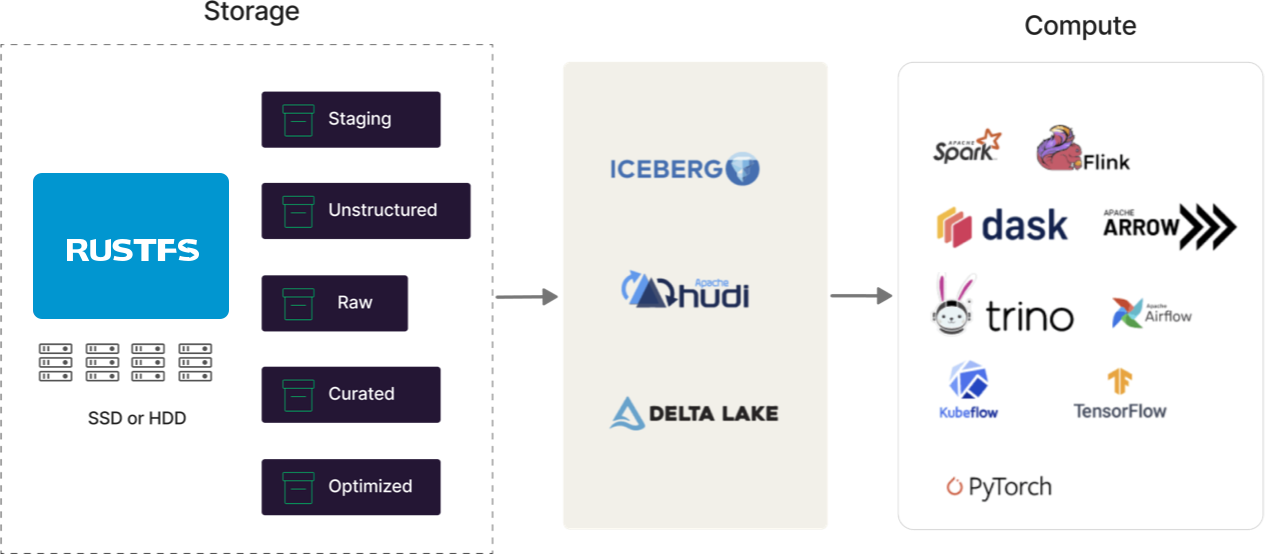
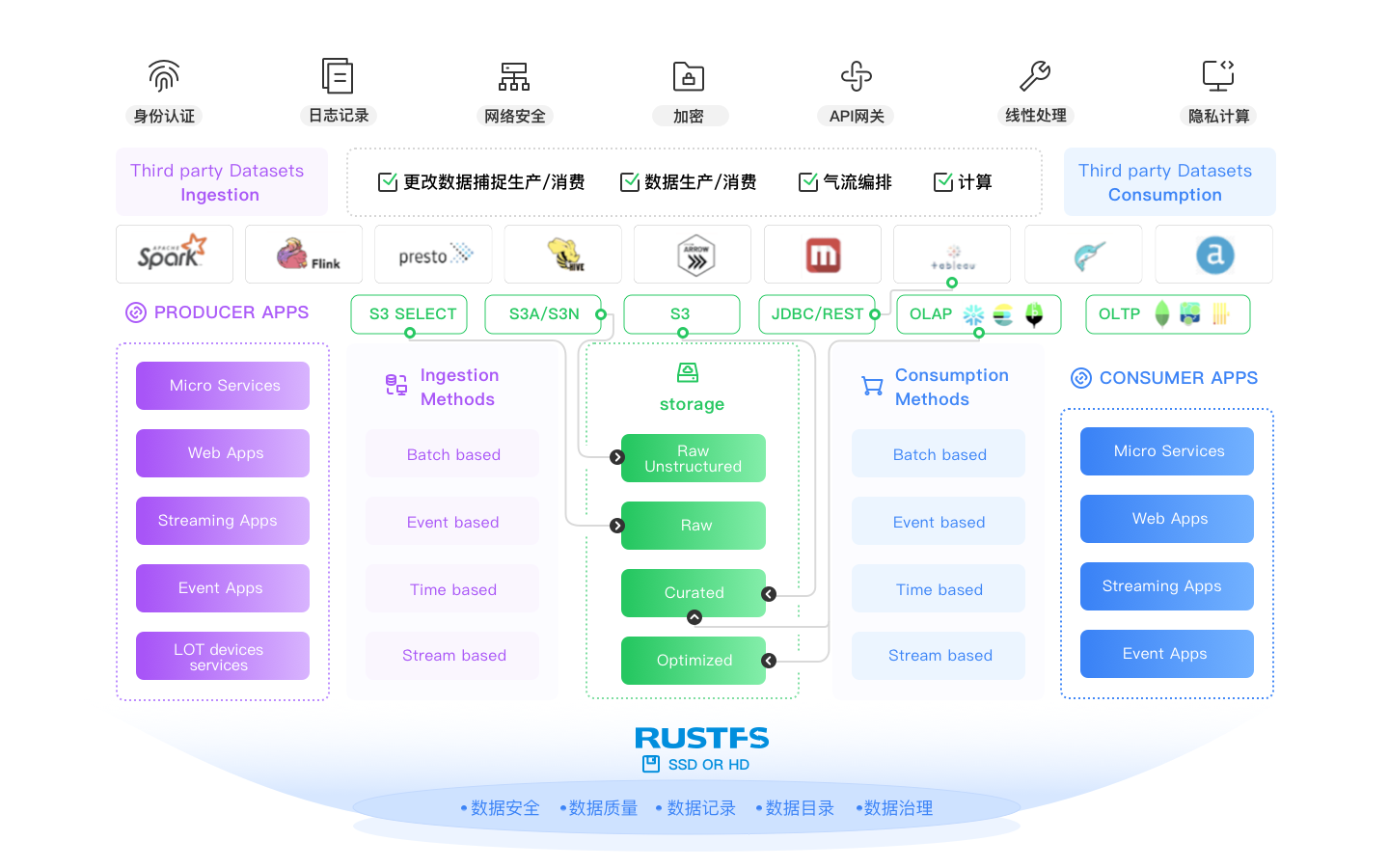
Moderne Data Lakes sind Multi-Engine, und diese Engines (Spark, Flink, Trino, Arrow, Dask, etc.) müssen alle in einer kohäsiven Architektur zusammengebunden werden. Moderne Data Lakes müssen zentralen Tabellenspeicher, portierbare Metadaten, Zugriffskontrolle und persistente Struktur bereitstellen. Hier kommen Formate wie Iceberg, Hudi und Delta Lake ins Spiel. Sie sind für moderne Data Lakes konzipiert, und RustFS unterstützt jedes von ihnen. Wir haben möglicherweise Meinungen darüber, welches gewinnen wird (Sie können uns immer fragen...), aber wir sind darauf festgelegt, sie zu unterstützen, bis es keinen Sinn mehr macht (siehe Docker Swarm und Mesosphere).
Cloud Native
RustFS wurde in der Cloud geboren und arbeitet nach Cloud-Prinzipien - Containerisierung, Orchestrierung, Microservices, APIs, Infrastructure as Code und Automatisierung. Aus diesem Grund funktioniert das cloud-native Ökosystem einfach mit RustFS - von Spark bis Presto/Trino, von Snowflake bis Dremio, von NiFi bis Kafka, von Prometheus bis OpenObserve, von Istio bis Linkerd, von Hashicorp Vault bis Keycloak.
Glauben Sie uns nicht aufs Wort - geben Sie Ihre bevorzugte cloud-native Technologie ein und lassen Sie Google die Beweise liefern.
Multi-Engine
RustFS unterstützt alle S3-kompatiblen Query-Engines, was bedeutet alle von ihnen. Sehen Sie die, die Sie verwenden, nicht - schreiben Sie uns eine Nachricht und wir untersuchen es.


Performance
Moderne Data Lakes benötigen ein Leistungsniveau, und noch wichtiger, Leistung bei der Skalierung, von der die alten Hadoop-Ära-Commodity-Stores nur träumen konnten. RustFS hat in mehreren Benchmarks bewiesen, dass es Hadoop übertrifft, und Migrationspfade sind gut dokumentiert. Das bedeutet, Query-Engines (Spark, Presto, Trino, Snowflake, Microsoft SQL Server, Teradata, etc.) performen besser. Das schließt auch Ihre AI/ML-Plattformen ein - von MLflow bis Kubeflow.
Wir veröffentlichen unsere Benchmarks für die Welt zum Sehen und machen sie reproduzierbar. Erfahren Sie, wie wir 325 GiB/s (349 GB/s) bei GET und 165 GiB/s (177 GB/s) bei PUT mit nur 32 handelsüblichen NVMe SSD-Knoten in diesem Artikel erreicht haben.
Leichtgewichtig
RustFS's Server-Binary ist < 100 MB in seiner Gesamtheit. Trotz seiner Kraft ist es robust genug, um in Rechenzentren zu laufen, aber immer noch klein genug, um bequem am Edge zu leben. Es gibt keine solche Alternative in der Hadoop-Welt. Für Unternehmen bedeutet das, dass Ihre S3-Anwendungen überall mit derselben API auf Daten zugreifen können. Durch die Implementierung von RustFS Edge-Standorten und Replikationsfähigkeiten können wir Daten am Edge erfassen und filtern und sie zur Aggregation und weiteren analytischen Implementierung an den übergeordneten Cluster liefern.
Dekomposition
Moderne Data Lakes erweitern die Dekompositionsfähigkeiten, die Hadoop aufgebrochen haben. Moderne Data Lakes haben Hochgeschwindigkeits-Query-Processing-Engines und Hochdurchsatz-Speicher. Moderne Data Lakes sind zu groß, um in Datenbanken zu passen, daher befinden sich Daten in Objektspeicher. Auf diese Weise können sich Datenbanken auf Query-Optimierungsfunktionalität konzentrieren und Speicherfunktionalität an Hochgeschwindigkeitsobjektspeicher auslagern. Durch das Halten von Daten-Subsets im Speicher und die Nutzung von Features wie Predicate Pushdown (S3 Select) und External Tables - haben Query-Engines größere Flexibilität.
Open Source
Unternehmen, die Hadoop adoptierten, taten dies aus Präferenz für Open-Source-Technologie. Als logischer Nachfolger - wollen Unternehmen, dass ihre Data Lakes ebenfalls Open Source sind. Deshalb gedeiht Iceberg und warum Databricks Delta Lake open-sourced hat.
Die Fähigkeiten, Freiheit von Vendor Lock-in und Komfort, die von Zehntausenden von Benutzern kommen, haben realen Wert. RustFS ist auch 100% Open Source und stellt sicher, dass Organisationen ihren Zielen treu bleiben können, wenn sie in moderne Data Lakes investieren.
Schnelles Wachstum
Daten werden ständig generiert, was bedeutet, sie müssen ständig ingested werden - ohne Verdauungsprobleme zu verursachen. RustFS ist für diese Welt gebaut und funktioniert out of the box mit Kafka, Flink, RabbitMQ und zahlreichen anderen Lösungen. Das Ergebnis ist, dass der Data Lake/Lakehouse zu einer einzigen Quelle der Wahrheit wird, die nahtlos auf Exabytes und darüber hinaus skalieren kann.
RustFS hat mehrere Kunden mit täglicher Datenaufnahme von über 250PB.
Einfachheit
Einfachheit ist schwer. Es erfordert Arbeit, Disziplin und am wichtigsten, Engagement. RustFS's Einfachheit ist legendär und ist ein philosophisches Engagement, das unsere Software leicht zu deployen, verwenden, upgraden und skalieren macht. Moderne Data Lakes müssen nicht komplex sein. Es gibt ein paar Teile, und wir sind darauf festgelegt sicherzustellen, dass RustFS am einfachsten zu adoptieren und zu deployen ist.
ELT oder ETL - Es funktioniert einfach
RustFS funktioniert nicht nur mit jedem Datenstreaming-Protokoll, sondern mit jeder Datenpipeline - jedes Datenstreaming-Protokoll und jede Datenpipeline funktioniert mit RustFS. Jeder Anbieter wurde ausgiebig getestet, und typischerweise haben Datenpipelines Resilienz und Performance.
Resilienz
RustFS schützt Daten mit Inline Erasure Coding für jedes Objekt, was weit effizienter ist als die HDFS-Replikationsalternativen, die niemals adoptiert wurden. Zusätzlich stellt RustFS's Bitrot-Erkennung sicher, dass es niemals korrupte Daten liest - erfasst und repariert korrupte Daten dynamisch für Objekte. RustFS unterstützt auch Cross-Region, Active-Active-Replikation. Schließlich unterstützt RustFS ein vollständiges Object-Locking-Framework, das Legal Hold und Retention (mit Governance- und Compliance-Modi) bereitstellt.
Software Defined
Der Nachfolger von Hadoop HDFS ist keine Hardware-Appliance, sondern Software, die auf Commodity-Hardware läuft. Das ist die Essenz von RustFS - Software. Wie Hadoop HDFS ist RustFS darauf ausgelegt, vollen Vorteil aus Commodity-Servern zu ziehen. In der Lage, NVMe-Laufwerke und 100-GbE-Netzwerke zu nutzen, kann RustFS Rechenzentren verkleinern und dadurch die operative Effizienz und Verwaltbarkeit verbessern. Tatsächlich reduzieren Unternehmen, die alternative Data Lakes bauen, ihren Hardware-Footprint um 60% oder mehr, während sie die Performance verbessern und die erforderlichen FTEs zur Verwaltung reduzieren.
Sicherheit
RustFS unterstützt mehrere ausgeklügelte serverseitige Verschlüsselungsschemas, um Daten zu schützen, wo immer sie sich befinden, ob in Bewegung oder in Ruhe. RustFS's Ansatz gewährleistet Vertraulichkeit, Integrität und Authentizität mit vernachlässigbarem Performance-Overhead. Server- und clientseitige Verschlüsselungsunterstützung mit AES-256-GCM, ChaCha20-Poly1305 und AES-CBC gewährleistet Anwendungskompatibilität. Zusätzlich unterstützt RustFS branchenführende Key Management Systems (KMS).