Infrastructure for Large-Scale Data
RustFS is engineered for scalability across all dimensions: technical, operational, and economic.
RustFS is designed to be cloud-native and can run as lightweight containers managed by external orchestration services like Kubernetes. The entire application is compiled into a single static binary (~100 MB) that efficiently uses CPU and memory resources even under high load. As a result, you can co-host large numbers of tenants on shared hardware.
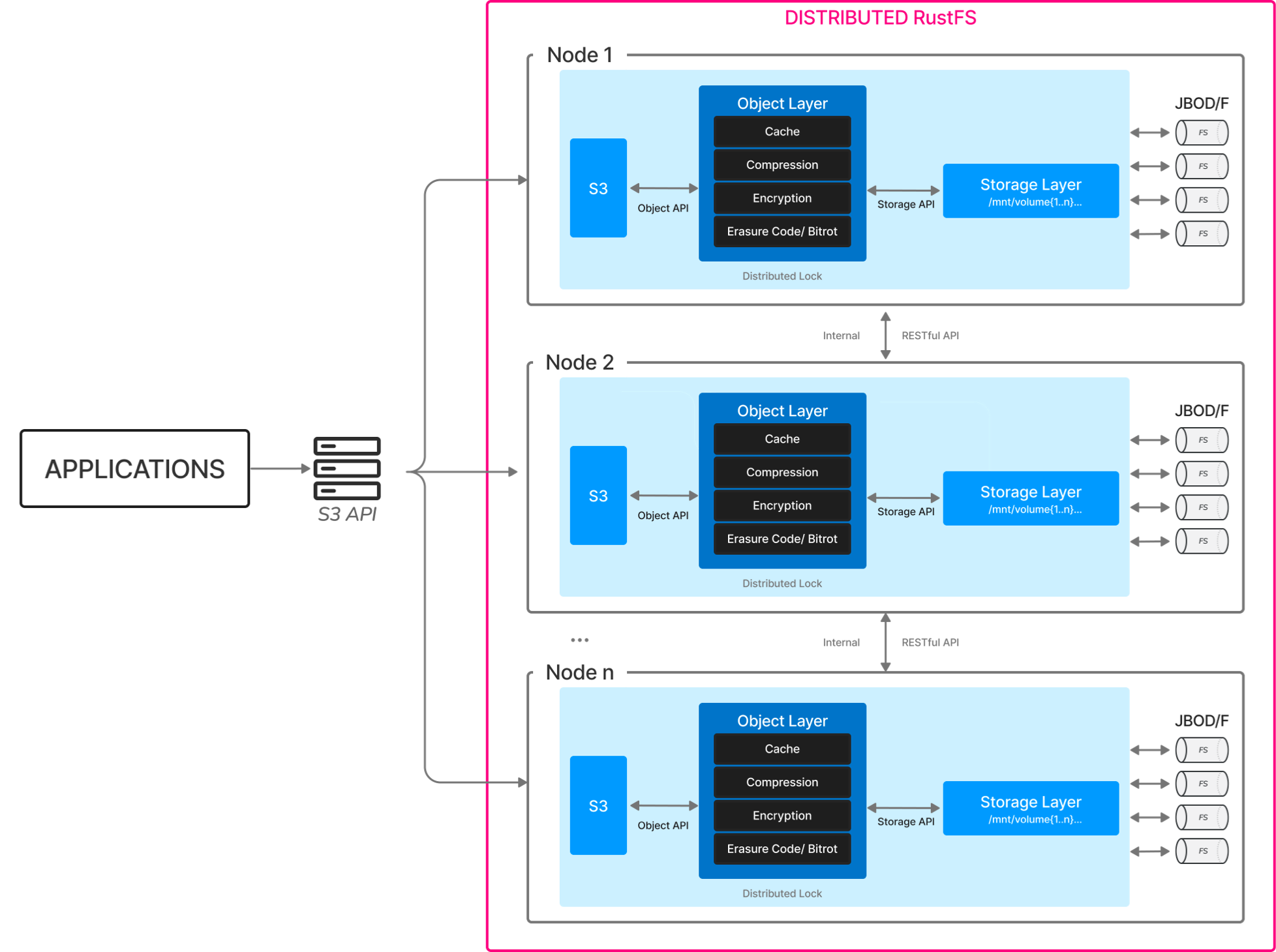
RustFS can run anywhere and on any cloud, but typically runs on commodity servers with locally attached drives (JBOD/JBOF). All servers in the cluster are functionally equal (fully symmetric architecture). There are no name nodes or metadata servers.
RustFS atomically writes data and metadata, eliminating the need for a separate metadata database. Additionally, RustFS performs all functionality (erasure coding, bitrot checking, encryption) as inline, strictly consistent operations. This results in extraordinary resilience.
Each RustFS cluster is a collection of distributed RustFS servers, with one process per node. RustFS runs as a single process in user space and uses lightweight coroutines to achieve high concurrency. Drives are grouped into erasure sets (see the erasure calculator here), and objects are placed on these sets using a deterministic hashing algorithm.
RustFS is designed for large-scale, multi-datacenter cloud storage services. Each tenant runs their own RustFS cluster, completely isolated from other tenants, enabling them to protect themselves from any disruption due to upgrades, updates, and security events. Each tenant scales independently by federating clusters across geographies.